
# kafka 概念
# 发布-订阅模型
通过发布-订阅模型,各个子模块之间做到解耦。各个子模块只需要知道自己需要往中间件——Kafka 里取值还是存值即可。简单的抽象模型如下图所示:

Kafka 的出现,做到了子系统之间的解耦合。因此,它也被称为「分布式日志提交系统」或者「分布式流处理系统」。下面是 Kafka 的一些基本概念:
# 消息和批处理
Kafka 处理的数据单元叫做「消息」,一种类似于数据库中「行」或者「记录」的概念。这些数据单元,对于 Kafka 而言,并没有特殊意义,都是字节数组。但是,每个消息可以拥有描述性的元数据——Key,这些 Key 通常用来表示消息应该存放的分区。为了效率,Kafka 里的消息都是批处理的,同一批(Batch)的消息主题和分区相同,这样的设计有助于减少单消息在网络传输带来的开销。当然,这种处理方式,也是一种在吞吐量和网络时延里的折中方案。
# 模式
为了让消息具备更加的可读性,Kafka 使用模式(Schema)来管理数据类型,如 JSON、XML 等等。为了向后兼容,或者做到可拓展性,选择合适的 Schema 非常重要。
# 主题和分区
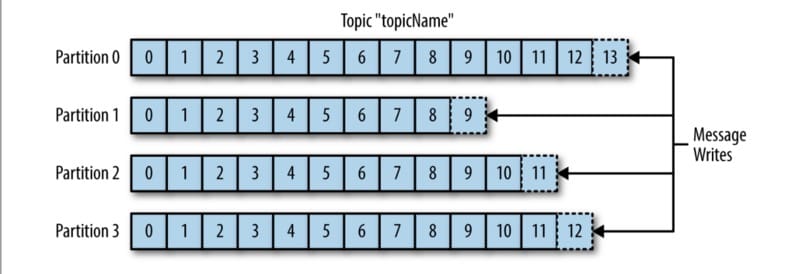
Kafka 里的消息按主题分类。鉴于 Kafka 里的消息是按追加、从头到尾读取的方式,使用分区可以大大提高 Kafka 的读取效率,也提供了系统的可拓展性。消息写入分区的方式入下图所示:

一个主题的消息,在类似于 Kafka 这样的系统中,被称为——「流」。
# 生产者和消费者
Kafka 有两个重要的概念:生产者和消费者;两个高级的客户端(Kafka 使用者)接口:集成 Kafka 的 Kafka Connect API 和操作 Kafka 的 Kafka Stream 接口。
生产者:创建消息的主体。可以通过不同的 Key 把消息发往不同的主题中去,还可以根据用户自定义的行为发送日志。 消费者:读取消息的主体。消费者追踪每个分区的 offset 的值,决定从哪里读取消息。Zookeeper 或者 Kafka 可以存储 offset 的值。共同消费一个主题的消费者,被称为「消费组」。消费组中的消费者和主题中的分区的队列关系,被称为「消费者所有权」。使用如下图所示的消费组,可以使 Kafka 更便于水平拓展:
# 中间人和集群
中间人:单个的 Kafka 服务器叫做「中间人」(Broker)。一个 Kafka 中间人,接收生产者发来的消费,分配偏移量,并存储入物理空间中去;同时,中间人还接收消费者的请求,把物理空间里的消息响应回去。 集群:一组协同工作的中间人叫做集群。在一个集群中,会有一个中间人充当集群控制器的角色,该控制器负责监控中间人的状态。在集群中,独占分区的中间人叫做该分区的「头头」(Leader)。多个中间人共享分区,可以使消息进行「主从复制」。当一个中间人挂掉,其它的中间人可接管头头的角色。当然前提是,接管头头角色的中间人之前可以和前头头联通。下图是一个集群里,不同中间人间复制消息的图示:

Kafka 还有一个重要的概念:保质期(Retention),表示消息在 Kafka 服务器里可以保留的时长。Kafka 可以根据不同的策略,配置服务器里消息的保质期。如:根据消息的大小(达到特定大小后失效)、根据时间(指定时间后过期)配置。
# 多集群
随着业务的拓展,如下需求通常会被提出:
- 数据类型分离
- 安全因素的数据隔离
- 多数据中心(灾备)
举个例子,不同集群间可以通过 MirrorMaker 工具进行数据复制。简而言之,就是通过该工具,从一个集群消费消息,然后向另外一个集群生产消息。下面是一个通过 MirrorMaker 进行集群中消息复制的图例:

# 为什么选择 Kafka
虽然有很多发布/订阅式的系统,但是选择 Kafka 是出于以下原因。
# 多生产者
Kafka 可以无缝接入多个生产者。多个消费者可以消费同一个主题内的消息,而无需知道该主题内的消息来自哪个生产者。一个简单的例子就是:多个微服务往同一个主题中投放消息,然后该主题的消息「聚合」了多个应用。
# 多消费者
Kafka 多消费者模型,表现为多个消费者互不干扰地消费同一主题内的消息。这也是 Kafka 和其它消息队列不同的地方。
# 基于磁盘的有效期
Kafka 中的消息会被写入磁盘,得益于 Kafka 灵活的消息过期策略,磁盘中的消息的有效期是可配置的。鉴于此,Kafka 不会有丢消息的危险。即便应用重启,它仍能够借助 Kafka 从结束的地方重新开始。
# 拓展性
Kafka 拥有灵活的拓展性配置,这意味着:用户可以根据需求拓展 Kafka 的 Broker 的数量来接收和处理任意数量的数据;多 Broker 可以接管单 Broker 中的错误。
# 高性能
上述 多生产者/消费者、可拓展性、灵活的有效期配置 造就了 Kafka 的高性能。
# Kafka 生态系统
基于 Kafka 的生产/消费模型,有一系列的生产和消费的技术。各种处理消息的技术,以统一的接口方式,构成了 Kafka 的生态系统。Kafka 生态系统如下图所示:

# 应用
# 活动跟踪
Kafka 可以记录用户访问前端应用的活动日志,这也是 LinkedIn 开发 Kafka 的初衷。Kafka 搜集的用户点击鼠标的事件、浏览页面的事件、更改个人主页的事件,均可以用作后端程序处理,使其变成有价值的产物。
# 系统监控和日志记录
可以向 Kafka 中发送系统的运行日志,通过分析这些日志,可以对系统的各个指标进行评估。同时,Kafka 记录的日志可供其它的日志分析系统消费。
# 发消息
Kafka 可以向其它应用发送中间件的消息,如:数据库有改动,可以将改动的信息发往应用程序。
# 流式处理
Kafka 提供的对数据的流式操作,和 Hadoop 的 Map/Reduce 模型类似,可以做到数据的实时处理。
# Kafka.原点
Kafka 设计的初衷是处理不同类型的数据,实现一个简单、结构化的高性能系统,以实时地分析用户行为和监控系统状态。 —— Jeff Weiner LinkedIn CEO
# Kafka 的诞生
由 Jay kreps 主导的开发团队希望构建一个能同时满足监控系统和追踪系统的消息系统,最初的目标是:
- 通过 push-pull 模型对生产者和消费者解耦
- 提供消息持久性支持多消费者
- 优化消息的高吞吐率
- 允许系统水平拓展
最终,开发出来的 Kafka 在接口上和典型的消息系统的 发布/订阅 一致,但在存储层上,更像一个日志聚合系统。借助 Apache Avro 进行消息序列化,Kafka 能够做到大规模的消息处理。