
# Logstash
# Logstash概述
# 集中、转换和存储数据
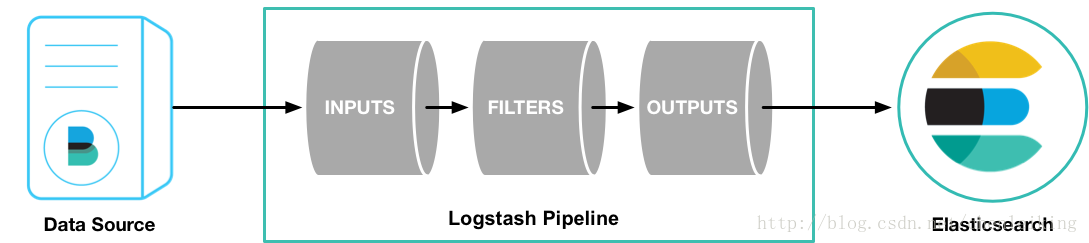
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。
# 输入、过滤器和输出
Logstash 能够动态地采集、转换和传输数据,不受格式或复杂度的影响。利用 Grok 从非结构化数据中派生出结构,从 IP 地址解码出地理坐标,匿名化或排除敏感字段,并简化整体处理过程。
# 采集各种样式、大小和来源的数据 (输入)
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。 Logstash 支持 各种输入选择 (opens new window) ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
# 实时解析和转换数据 (过滤器)
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
利用 Grok 从非结构化数据中派生出结构
从 IP 地址破译出地理坐标
将 PII 数据匿名化,完全排除敏感字段
简化整体处理,不受数据源、格式或架构的影响
我们的过滤器库 (opens new window)丰富多样,拥有无限可能。
# 选择您的存储库,导出您的数据 (输出)
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。
Logstash 提供众多输出选择 (opens new window),您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
从 Logstash 的名字就能看出,它主要负责跟日志相关的各类操作,在此之前,我们先来看看日志管理的三个境界吧
境界一
『昨夜西风凋碧树。独上高楼,望尽天涯路』,在各台服务器上用传统的 linux 工具(如 cat, tail, sed, awk, grep 等)对日志进行简单的分析和处理,基本上可以认为是命令级别的操作,成本很低,速度很快,但难以复用,也只能完成基本的操作。
境界二
『衣带渐宽终不悔,为伊消得人憔悴』,服务器多了之后,分散管理的成本变得越来越多,所以会利用 rsyslog 这样的工具,把各台机器上的日志汇总到某一台指定的服务器上,进行集中化管理。这样带来的问题是日志量剧增,小作坊式的管理基本难以满足需求。
境界三
『众里寻他千百度,蓦然回首,那人却在灯火阑珊处』,随着日志量的增大,我们从日志中获取去所需信息,并找到各类关联事件的难度会逐渐加大,这个时候,就是 Logstash 登场的时候了
2
3
4
5
6
7
8
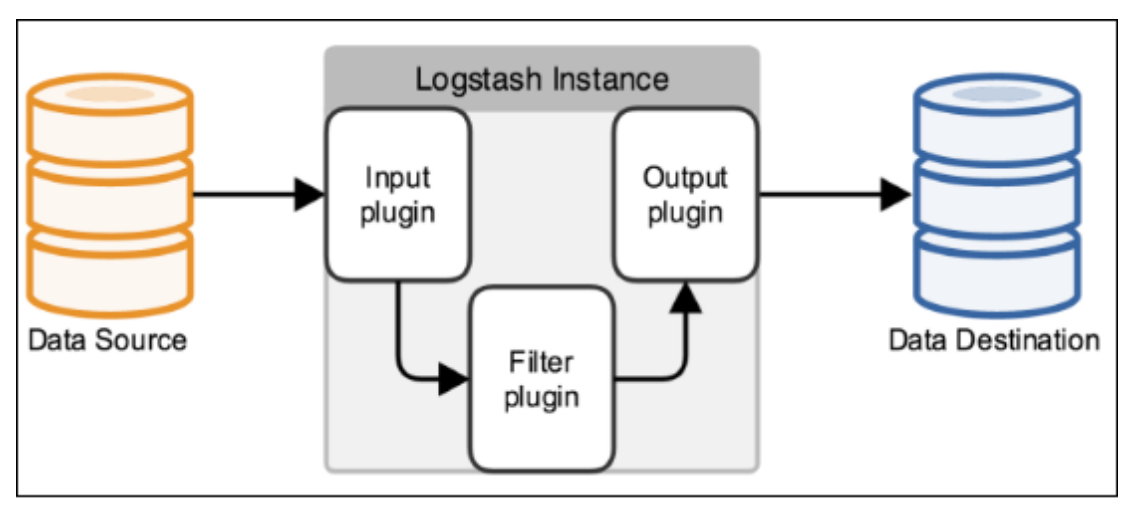
Logstash 的主要优势,一个是在支持各类插件的前提下提供统一的管道进行日志处理(就是 input-filter-output 这一套),二个是灵活且性能不错
logstash里面最基本的概念(先不管codec)
logstash收集日志基本流程:
input–>filter–>output
input:从哪里收集日志
filter:对日志进行过滤
output:输出哪里
2
3
4
5
6
7
# 下载安装
## 解压安装
上传包
tar -xf 包名
cd /opt/logstash-7.2.0
## 启动
./bin/logstash -f 配置文件名
## 后台运行
nohup ./bin/logstash -f 配置文件名 &
2
3
4
5
6
7
8
9
10
11
12
13
# filebeat 到 logstash
filebeat 配置
修改filebeat output 输出
注释如下内容
#output.elasticsearch:
# # Array of hosts to connect to.
# hosts: ["localhost:9200"]
去掉注释如下内容
output.logstash:
#The Logstash hosts
hosts: ["127.0.0.1:5044"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
logstash 配置
## 创建 logstash 配置名称
2
在
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "nginx_log-%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
启动 ./bin/logstash -f logstash.yml
Nginx 日志过滤日志
input {
beats {
port => 5044
}
}
filter {
grok {
## grok数据格式整理,可以去官网学习logstash grok格式
match => [
"message", "%{IPORHOST:http_host} %{IPORHOST:user_ip} - - \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion:float})?|%{DATA:rawrequest})\" %{NUMBER:response:int} (?:%{NUMBER:bytes:int}|-) %{QS:referrer} %{QS:useragent} (?:%{NUMBER:request_time:float}|-) (?:%{NUMBER:upstream_time:float}|-)"
]
}
geoip {
source => "user_ip"
## 用户IP地址
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
useragent {
target => "ua"
source => "useragent"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "nginx1-%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
./bin/logstash -f logstash_nginx.yml
# filebeat 到 redis 到 logstash
# 安装redis
在 elk-1 安装redis
yum install -y epel-release
yum install -y redis
systemctl start redis
## 检查redis 是否启动
ps -ef | grep redis
如下:已经正常启动
[root@elk-1 kafka-2.3.0-src]# ps -ef | grep redis
redis 24228 1 0 07:23 ? 00:00:01 /usr/bin/redis-server 127.0.0.1:6379
root 24261 22693 0 07:45 pts/3 00:00:00 grep --color=auto redis
2
3
4
5
6
7
8
9
10